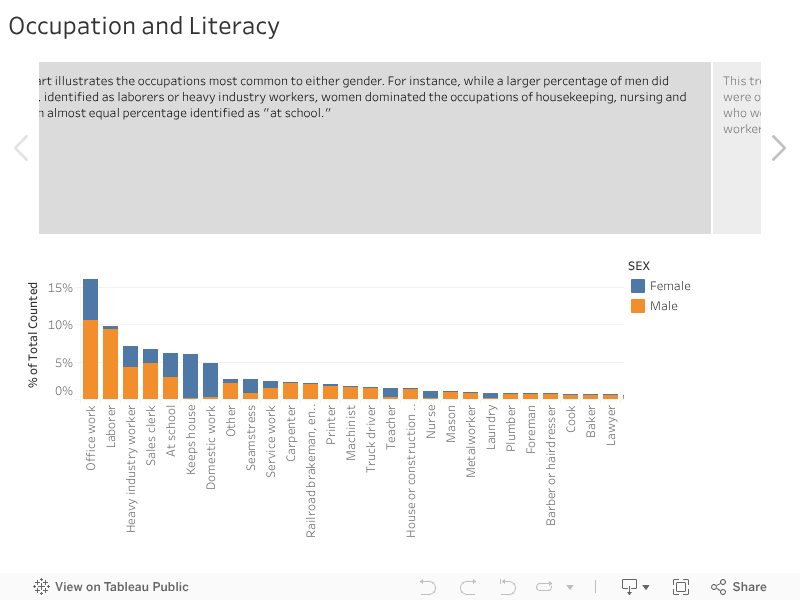
Above is my attempt to put all three visualizations in a story. I’m not sure if it is showing up.
Below you will see the visualizations separately. I’m not a fan of how WordPress is rendering them. The details are really small and they seem blurry.
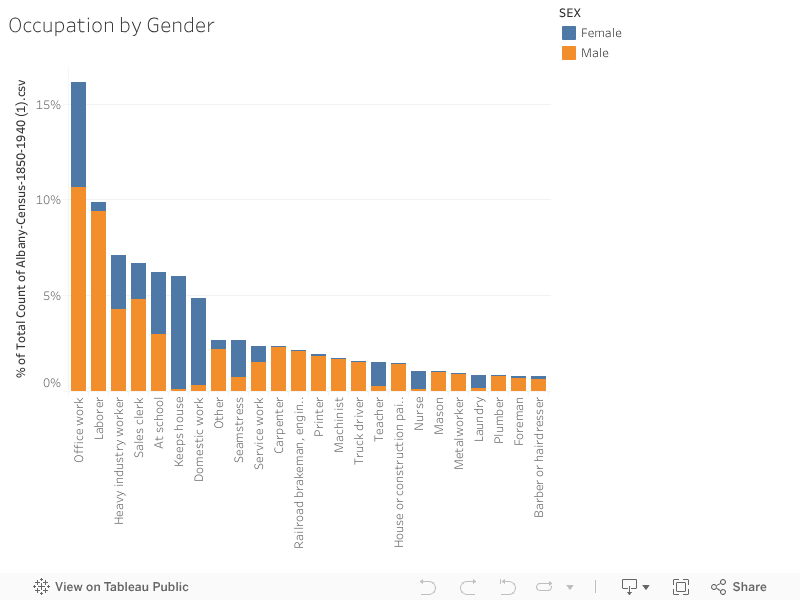
This bar chart illustrates the occupations most common to either gender. For instance, while a larger percentage of men did office work, identified as laborers or heavy industry workers, women dominated the occupations of housekeeping, nursing and teaching. An almost equal percentage identified as “at school.”
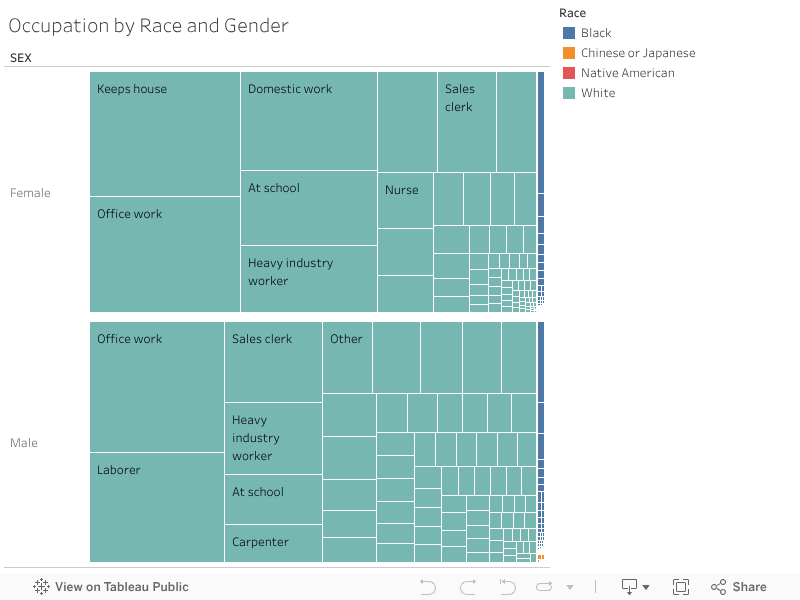
This tree map break occupation down even further by gender and race. We can see that the majority of white men and women were occupied indoors on service positions such as office work or keeping house. Of the small number of people of other races who were counted, we can see that the largest percent of black men were occupied as laborers, and black women as domestic workers.
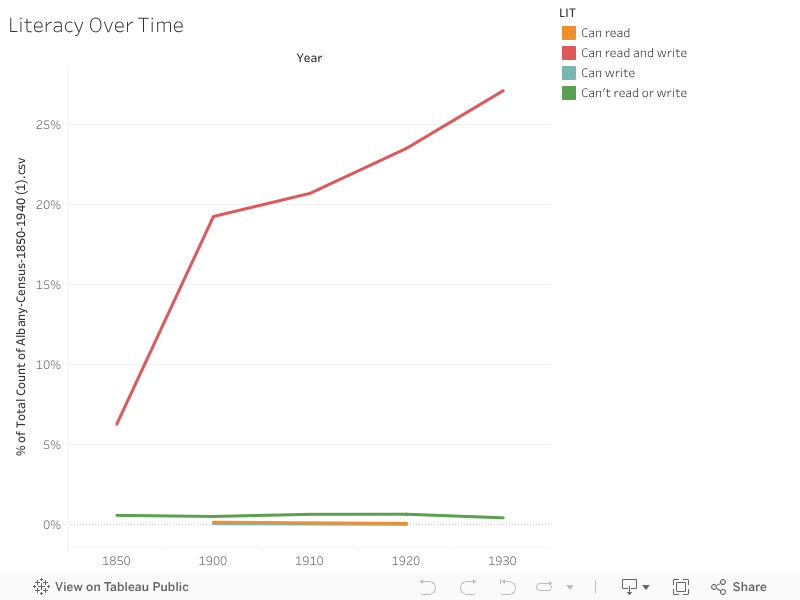
By viewing literacy rates over time, we can see a sharp spike in people who were identified as being able to read and write after the 1850 census.
Reflections
My favorite work in this course so far has been the data cleaning using Open Refine. I’ve spent many hours trying to make excel and google sheets do work that is made so much simpler by Open Refine. I’ve already started using the tool on my own data, and it’s amazing.
I am recognizing that as a I prep my data to do network analysis, by looking for the same people across multiple entries, that I could be more prone to “lumping” names together, because I’d rather see a more connected network of creditors and debtors than a less connected network. So I am trying to go thoughtfully through my data as I make decisions.
I’d like to fool around a bit more with writing code to scrape data from websites. Based on our experience with the Albany newspapers and Carleton Papers, I’m curious to see if I could generate a spreadsheet from Find a Grave results from Dutchess County. It would help me to have an easily searchable list of names in the county. However, I’m still a little unclear as to the legality/politesse of data scraping.